UVE Data Flow and Monitoring
Data Sources
Weibo UVE Team serves billions requests everyday, consequently, we have to process billions data everyday.
The primary data sources include:
- Requests log
- Response log
- ADs impression log
- ADs actions(click, like, follow, etc)
- Internal service logs(ADs Bid, ADs rendering, etc)
Data Flow Overview
The following diagram shows the overall data flow of UVE.
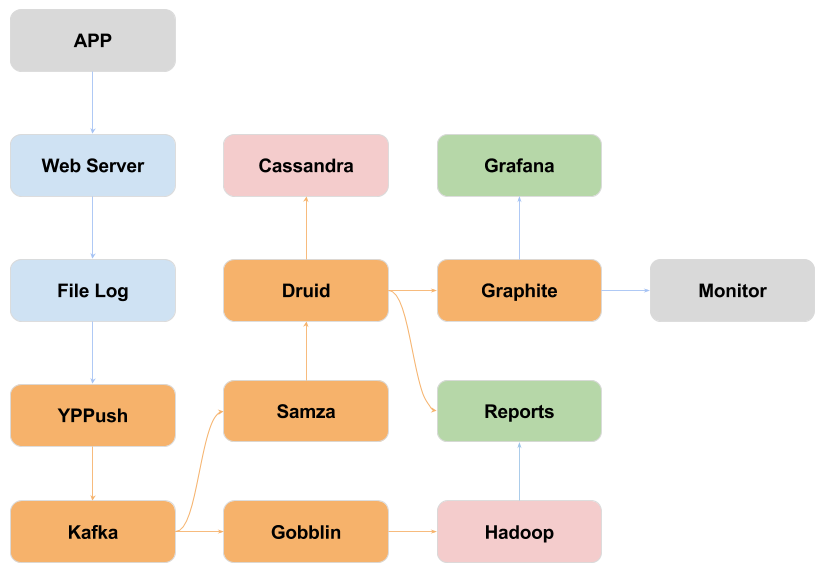
Data Transfer
As the diagram shows, many data sources are log files. In order to process the logs in realtime, we developed YYPush to transfer log files to Apache Kafka.
Gobblin is used to persist data onto HDFS, on which offline processing is performed.
Realtime processing is implemented with Apache Samza and Druid.
Data Storage
HDFS is our primary data storage, but due to some reason, the Apache Cassandra is used as the deep storage of Druid.
Data Analysis
Realtime
Thanks to Druid, realtime data analysis become much more straightforward and flexible.
Offline
Beside realtime analysis, we have to do some more complex offline processing and analysis. Most of the offline processing is based on Hadoop MapReduce, Hive, HBase, etc.
Data Monitoring
Monitoring is also very important. We have to discover what’s going wrong when a new feature is released in realtime, and we want to be notified when some accident occurred or the impression is not as expected.
Graphite makes our work much easier for realtime monitoring. Based on Graphite, we could easily monitor our data horizontally and vertically. The horizontal means compare current data with historical data, and vertical means compare data from different sources at the same time point, as the following diagram shows.
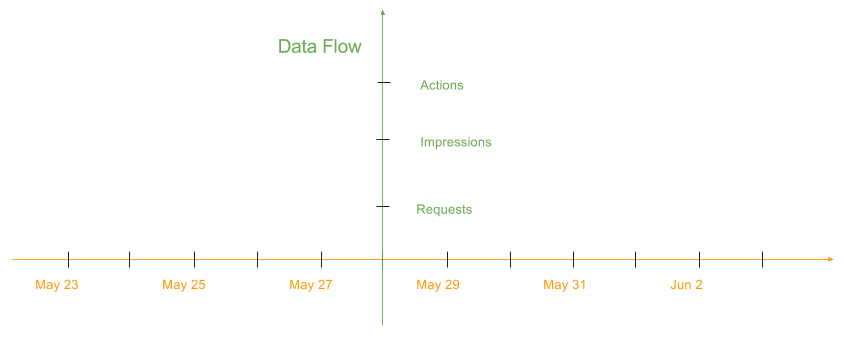
There are many monitoring tools that work with Graphite, such as Graphite-beacon, Cabot, for more information, see Tools That work with Graphite